The Illusion of Correctness: Emerging Layers of Context
Your agent has read the code. It can even read the docs. But does it understand the decisions that shaped the code? The context that lives in people's heads, not in files? That's the layer agents struggle with most, and it's the one that causes the most expensive failures.
The benchmark numbers get quoted a lot. Some setups now clear 80% on SWE-bench Verified. Scale AI's SWE-bench Pro, built to resist contamination, using real enterprise codebases and multi-step task chains that mirror actual development work, puts those same frontier models at 23%. The gap isn't simply a model quality problem. Scale's own analysis attributes it to contamination resistance, task diversity, underspecified requirements, and stricter testing realism. But the failure mode that shows up most consistently in production analysis is more specific: agents failing on tasks where the rationale behind existing decisions isn't accessible. Not the code. The reasoning behind it.
Here's a frame that's been useful.
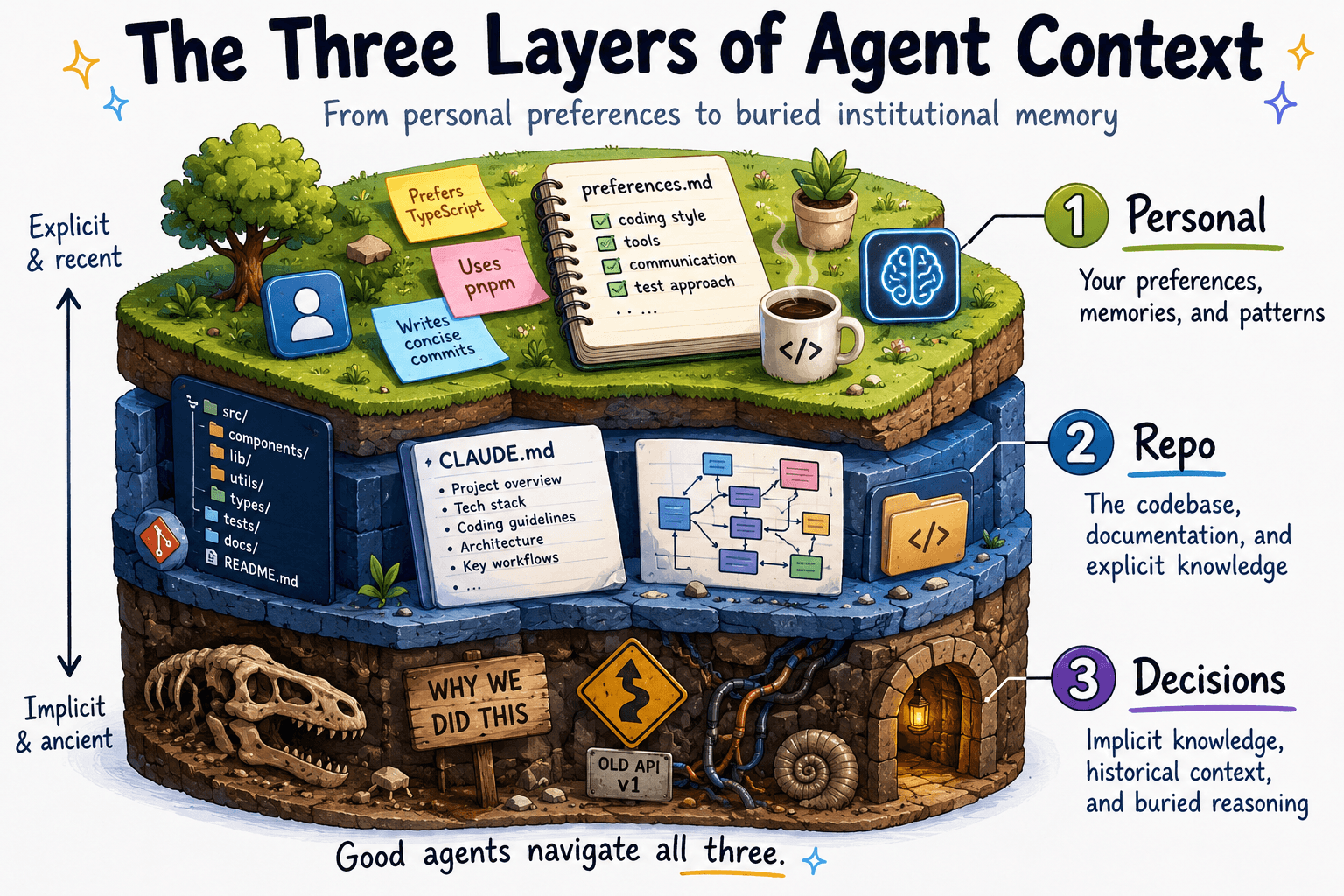
Coding agents draw from three layers of context. Each has a different owner, a different decay rate, and a different relationship to what agents actually get wrong.
Layer 1 — Personal. Memory MCP tools, a ~/preferences.md, the notes you've started keeping because the agent kept asking the same clarifying questions. This is the agent learning how you work: naming conventions, what you always catch in review, the formatting it should just get right. Cheap to maintain, decays slowly, owned entirely by you.
Layer 2 — Repo. CLAUDE.md, AGENTS.md, in-repo architecture docs, the README someone actually keeps current. This is the agent learning what it's working on: conventions, constraints, structure. In a well-maintained monorepo, Layer 2 does substantial work — the agent navigates cross-service concerns through the code itself. For those teams, the gap discussed below is narrower than it is for fragmented polyrepo setups. But even in a mature monorepo, Layer 2 has a characteristic weakness: it captures what the code does and how it should be written. It almost never captures why things are the way they are.
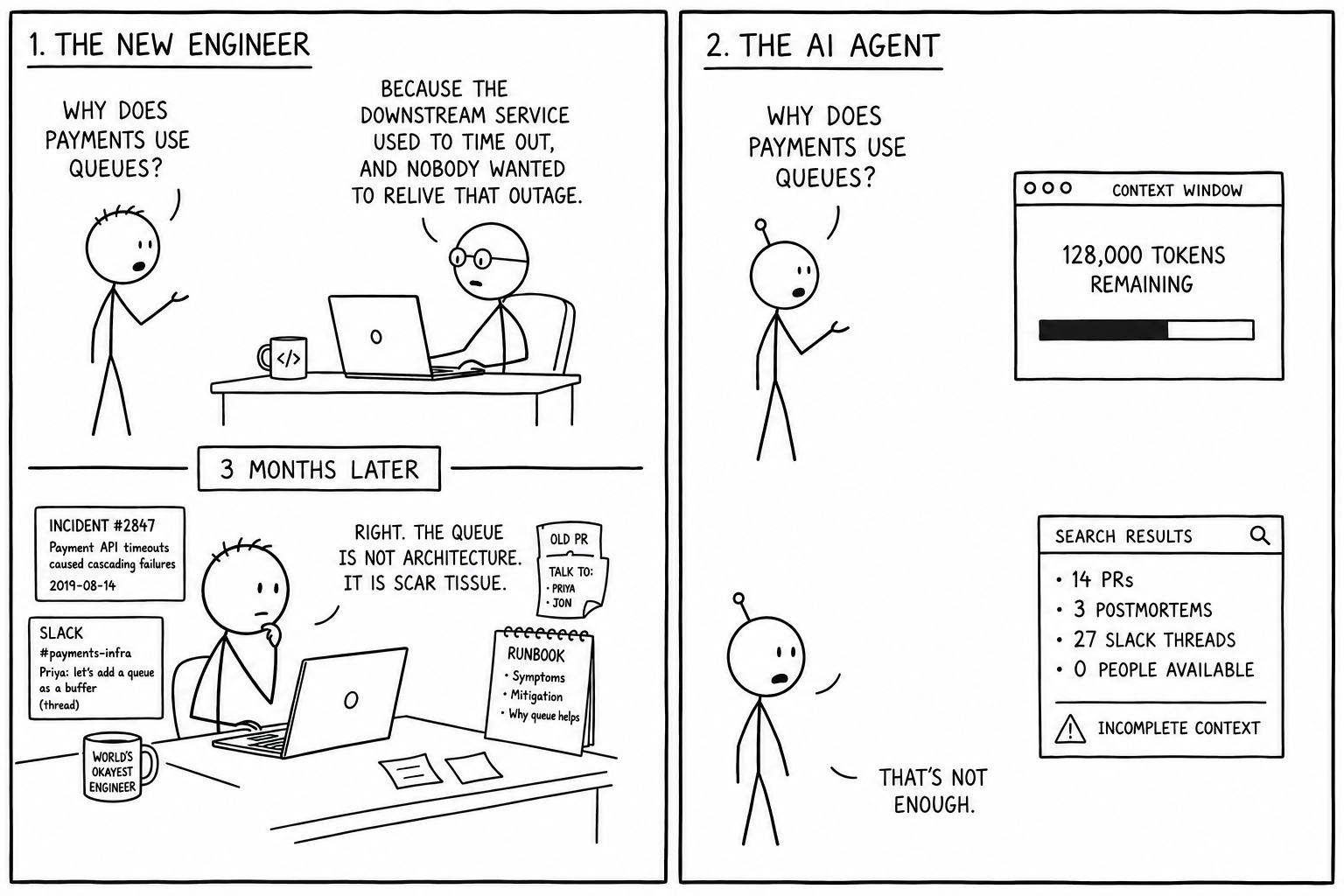
Layer 3 — Decisions. Why the payment service uses message queues instead of direct API calls. Why the retry cap is 2. Why Service C still uses the old auth library. Enterprise codebases are layered with decisions made for reasons that no longer exist, workarounds for problems that have since been solved, and constraints that live only in people's heads. As Augment Code puts it: "This context isn't documented. New engineers learn it through months of questions and mistakes. AI agents don't have months." Ryan J. Salva, Senior Director of Product Management at Google, made the same point to MIT Technology Review in January 2026: "A lot of work needs to be done to help build up context and get the tribal knowledge out of our heads."
Here's the honest part: Layer 3 isn't missing. It was normalised.
The decision context exists in code review threads, old Slack channels, postmortems, the architecture doc nobody links to. The reason it was never consolidated is that teams didn't need it to be. Senior engineers were adequate synthesisers. They held the map in their heads, navigated it under pressure, and updated it informally when things changed. The synthesis tax, the cost of reconstructing why from wherever it had drifted, was real but manageable. It got priced into what senior engineering looks like, not into a problem anyone was racing to solve.
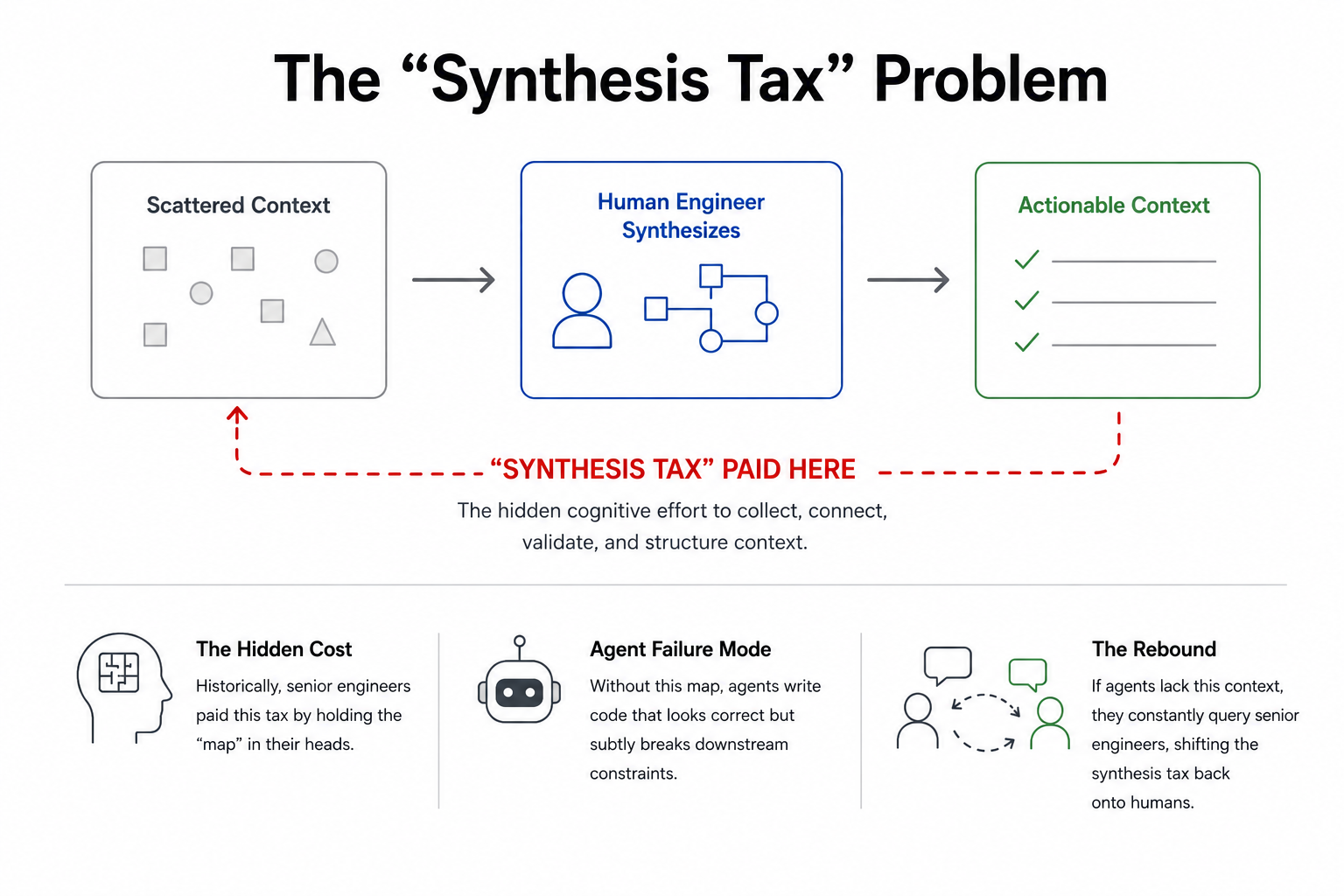
That calculus changes when agents enter the loop.
An agent operating without decision context doesn't fail loudly. It fails in the mode that's hardest to catch: confidently plausible, subtly wrong. It produces code that looks correct, passes review, and surfaces a missed constraint somewhere downstream. Augment Code's analysis of enterprise deployments, and they're a vendor in this space, so the figure should be read accordingly, puts coordination failures in over 60% of enterprise deployments down to missing architectural and historical context, not coordination failures per se. A VentureBeat survey of enterprise AI organisations in 2026 found integration and governance issues as the dominant failure mode, ahead of model capability.
There is also a second failure mode, quieter and more expensive in aggregate: the synthesis tax bounces back. The agent asks what it can't answer from context, and a senior engineer pays it again in a review comment, in a Slack thread, in a patient explanation. You haven't reduced the load on the people who carry the map. You've added a new thing asking them for it.
The corrective isn't more documentation that nobody reads, and it isn't a better search box for the haystacks you already have. Search returns a pile of documents to synthesise. The synthesis is still paid by a human, under pressure, against the clock. What's needed is the reconciled, sourced answer that a staff engineer would give, available at the moment of action, through the agents engineers are already running.
The synthesis tax was always there. Agents just made it expensive again.
That's what Ardelio is built for: not another place to look, but the answer a senior engineer would give, wired into the coding agents your team is already using.
Sources
- Scale AI, "SWE-bench Pro" leaderboard and methodology (2025–2026). https://labs.scale.com/leaderboard/swe_bench_pro_public — GPT-5 and Claude Opus 4.1 at ~23% on the public Pro set. Scale attributes difficulty to contamination resistance, task diversity, underspecified issues, and stricter testing — context completeness is one factor among several.
- Augment Code, "What Is Agentic Swarm Coding?" (Feb 2026). https://www.augmentcode.com/guides/what-is-agentic-swarm-coding-definition-architecture-and-use-cases — Source of the 60%+ enterprise failure figure and the "AI agents don't have months" characterisation. Augment Code is a vendor in this space; the 60% figure is their own analysis, not independent research.
- Ryan J. Salva (Google), quoted in MIT Technology Review (January 2026). — "A lot of work needs to be done to help build up context and get the tribal knowledge out of our heads."
- VentureBeat / Wallaroo.AI, "The Agentic Reckoning" (June 2026). https://venturebeat.com/resources/the-agentic-reckoning-enterprise-ai-organizations-have-a-runtime-problem-not-a-model-problem — Integration and governance challenges cited as dominant failure mode; model capability cited by 17% of respondents.